
Hay una frase que se repite mucho cuando alguien empieza a estudiar inteligencia artificial: "la retropropagación es el corazón del aprendizaje automático". Y es verdad. Pero esa frase, sin contexto matemático, es vacía.
Para entender de verdad por qué una red neuronal aprende, hay que entender lo que sucede geométricamente en su interior. Y eso requiere un punto de partida: el álgebra lineal.
Vectores: una flecha en el espacio
Un vector es, en esencia, una flecha. Matemáticamente, es un conjunto de números que describe un desplazamiento en un espacio.
En dos dimensiones, un vector se escribe así:
v = [1, 2]
El primer número indica cuánto nos movemos en el eje x. El segundo, cuánto en el eje y. Nada más.
En tres dimensiones, el mismo principio se extiende:
v = [3, 1, -2]
Tres espacios a la derecha en x, uno hacia arriba en y, dos hacia "atrás" en z. Cada componente adicional es simplemente una dimensión más en la que podemos movernos.
Este concepto, tan simple, es el ladrillo de todo lo que viene.
Vectores unitarios: los guardianes del espacio
Antes de entrar en transformaciones, necesitamos hablar de los vectores unitarios: los vectores que definen cómo se comporta nuestro espacio.
En un plano bidimensional, tenemos dos:
- î (i-hat): se mueve un espacio a la derecha, ninguno arriba →
[1, 0] - ĵ (j-hat): se mueve un espacio arriba, ninguno a los lados →
[0, 1]
Estos son nuestros vectores base. Son los ejes sobre los que descansa todo el espacio. Cualquier vector que imaginemos -digamos [4, -3]- no es otra cosa que una combinación de estos dos: cuatro veces î, menos tres veces ĵ.
Esto nos lleva al siguiente concepto.
Subespacio generado, dependencia e independencia lineal
Con dos vectores base y sus infinitas combinaciones lineales (escalarlos, sumarlos), generamos lo que se llama el subespacio generado: el conjunto de todos los puntos que podemos alcanzar.
Con î y ĵ en dos dimensiones, ese subespacio es todo el plano. Podemos llegar a cualquier punto.
Pero hay un problema que puede ocurrir.
Supongamos que nuestras bases son [3, 2] y [6, 4]. Si miramos con atención, el segundo vector es exactamente el doble del primero. Son el mismo vector, solo escalado. Esto se llama dependencia lineal.
Cuando dos vectores base son dependientes, el espacio bidimensional "se aplana": en lugar de abarcar todo el plano, nuestras combinaciones quedan atrapadas en una sola línea. Perdemos una dimensión entera. Perdemos información.
En una red neuronal, la dependencia lineal es un síntoma de que algo está mal en la arquitectura. El modelo no puede aprender lo que necesita aprender porque el espacio que habita es insuficiente.
Transformaciones lineales: matrices que doblan el espacio
Llegamos al concepto central de este artículo.
Una transformación lineal es una operación que toma nuestro espacio y lo modifica: lo estira, lo rota, lo comprime, lo cizalla. Y matemáticamente, esa operación se representa con una matriz.
¿Cómo lo hace? Transformando los vectores base.
Cuando una matriz actúa sobre un espacio, redefine î y ĵ. Si los nuevos î y ĵ son perpendiculares y de longitud 1, el espacio se rota. Si uno de ellos se estira, el espacio se escala. Si se deforman asimétricamente, obtenemos una cizalla.
Algunos ejemplos concretos de transformaciones conocidas:
- Rotación: gira todos los vectores un ángulo determinado.
- Escalado: estira o comprime el espacio en una o más dimensiones.
- Cizalla (shear): inclina el espacio, manteniendo un eje fijo y desplazando el otro.
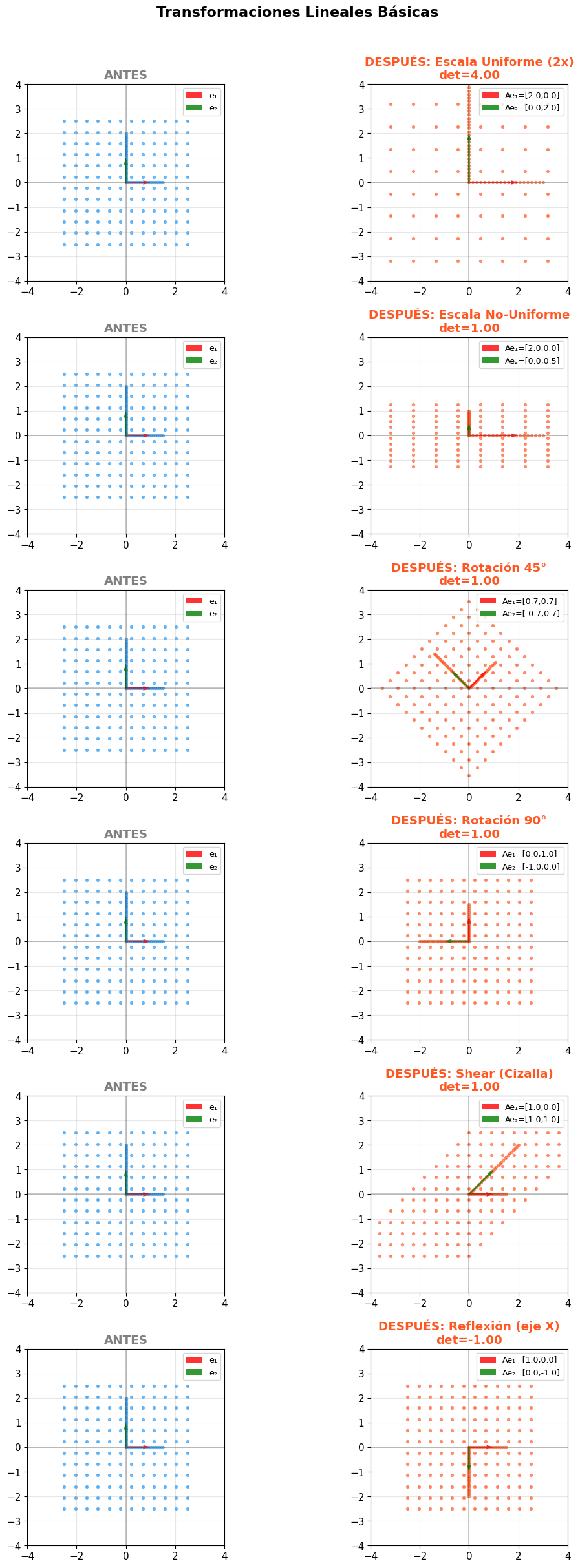
La intuición clave: la matriz no es una tabla de números; es una descripción de cómo se mueve el espacio.
Multiplicación de matrices: composición de transformaciones
¿Qué sucede cuando aplicamos dos transformaciones lineales una tras otra? Obtenemos una composición lineal, y eso se expresa multiplicando sus matrices.
Aquí hay algunas reglas fundamentales:
Las dimensiones deben ser compatibles. Si tenemos una matriz de m×n y otra de n×p, podemos multiplicarlas. Las n internas deben coincidir. El resultado es una matriz de m×p.
El orden importa. La multiplicación de matrices no es conmutativa: A·B ≠ B·A. No es lo mismo escalar el espacio y luego rotarlo, que rotarlo primero y luego escalarlo. El resultado geométrico es distinto.
Sí es asociativa. A·(B·C) = (A·B)·C. Podemos agrupar las transformaciones como queramos.
Cómo se multiplican: combinación lineal de columnas
El método más intuitivo para entender la multiplicación es la combinación lineal de columnas. Se lee de derecha a izquierda.
Dadas dos matrices A y B de 2×2:
A = [[2, 3],
[3, 4]]
B = [[1, 2],
[1, 3]]
Para obtener la primera columna de C = A·B, tomamos la primera columna de B ([1, 1]) y la usamos como escalares sobre las columnas de A:
1·[2,3] + 1·[3,4] = [5, 7] → primera columna de C
Para la segunda columna, repetimos con la segunda columna de B ([2, 3]):
2·[2,3] + 3·[3,4] = [13, 18] → segunda columna de C
Resultado:
C = [[5, 13],
[7, 18]]
Cada columna del resultado es una combinación lineal de las columnas de A, ponderada por los coeficientes de B. No es magia: es geometría.
Rango y determinante: cuánto espacio queda
Dos métricas que dicen mucho sobre lo que una matriz hace al espacio:
El determinante representa el factor de escala del área (en 2D) o del volumen (en 3D) que produce la transformación.
- Determinante positivo: el espacio se expande o contrae, pero conserva su orientación.
- Determinante = 0: el espacio colapsa. Una dimensión desaparece. Se pierde información. Es el equivalente matricial de la dependencia lineal.
- Determinante negativo: el espacio se invierte (como girar un guante al revés).
El rango mide cuántas dimensiones "sobreviven" tras la transformación. Una matriz de rango pleno preserva toda la información. Una de rango reducido la comprime.
En el contexto de redes neuronales, un rango reducido en alguna capa es una señal de que el modelo está perdiendo capacidad expresiva.
Y entonces... ¿qué tiene que ver todo esto con la retropropagación?
Todo.
La fórmula de una red neuronal de dos capas se ve así:
y = W₂ · ReLU(W₁ · x + b₁) + b₂
Parece distante de la ecuación de la recta que aprendimos en la secundaria (y = mx + b), pero en realidad es su generalización directa. Desglosada, la lógica es esta:
- W₁ · x es una transformación lineal: la matriz de pesos W₁ transforma el vector de entrada x.
- + b₁ desplaza el resultado en el espacio (traslación).
- ReLU(·) es la operación no lineal: corta todos los valores negativos y los deja en cero.
- W₂ · (resultado) aplica una segunda transformación lineal.
- + b₂ hace el desplazamiento final.
Esto es una composición de transformaciones. Exactamente lo que vimos en la sección de multiplicación de matrices, pero con una vuelta de tuerca: entre las dos transformaciones lineales, se inserta una función no lineal.
¿Por qué ReLU? Sin ella, cualquier combinación de transformaciones lineales sigue siendo lineal. Podríamos apilar cien capas y obtener exactamente el mismo resultado que con una sola. La no linealidad es lo que permite que la red doble y deforme el espacio para aprender patrones complejos.
La retropropagación no es más que calcular cuánto contribuyó cada peso (cada matriz W) al error final, recorriendo esa composición de transformaciones en sentido inverso. Y ese recorrido inverso se hace con las herramientas del cálculo diferencial aplicadas sobre... multiplicaciones de matrices.
El álgebra lineal es el lenguaje. La retropropagación es lo que se dice en ese lenguaje.
Cierre
Entender una red neuronal como una secuencia de transformaciones geométricas cambia la forma en que se la diagnostica y se la diseña.
Cuando un modelo no converge, cuando las capas colapsan, cuando el gradiente explota o desaparece, hay una explicación geométrica detrás. Y esa explicación vive en el álgebra lineal.
Este artículo cubrió vectores, transformaciones, multiplicación de matrices y su relación directa con la arquitectura de una red neuronal. En los próximos artículos de esta serie entraremos en las otras dos patas del deep learning: el cálculo que hace posible la retropropagación, y la estadística que justifica por qué funciona.
¿Querés profundizar en alguno de estos temas o aplicarlos a un proyecto concreto? Escribinos.
Eje Z · Córdoba, Argentina · Software a medida para empresas que quieren crecer sin depender de soluciones genéricas.